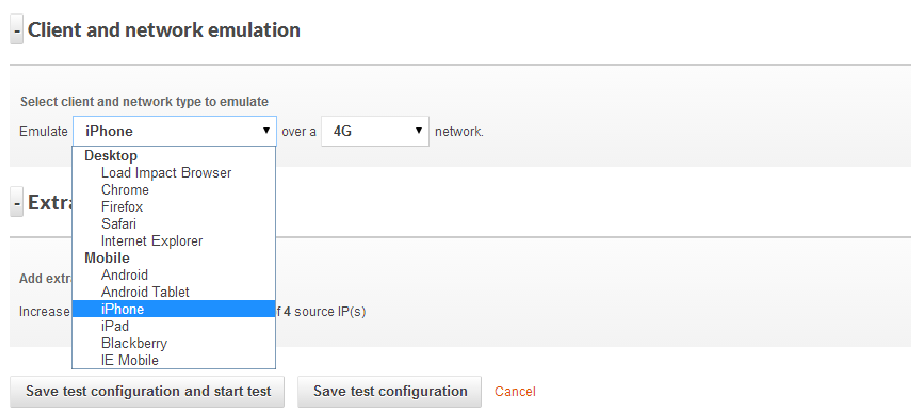
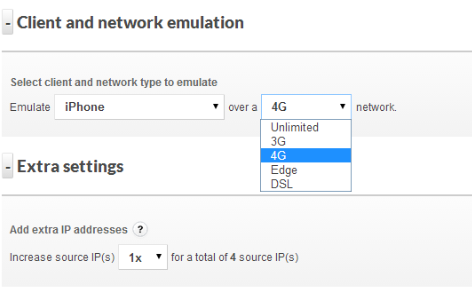
How and where you execute load and performance testing is a decision that depends on a number of factors in your organization and even within the application development team.
It is not a clear cut decision that can be made based on the type of application or the number of users, but must be made in light of organizational preferences, cadence of development, timeline and of course the nature of the application itself and technical expertise currently on staff.
In this post we will provide some context around some of the key decision points that companies of all size should consider when putting together load NS performance testing plans.
This discussion is really an amalgamation of On-Premise versus SaaS/Open-Source versus Commercial Services.
In the load testing space there are commercial offerings that offer both SaaS and on-premise solutions as well as many SaaS only solutions for generating user load.
From an open source perspective, JMeter is the obvious choice (there are other less popular options such as FunkLoad, Gatling, Grinder, SOAPUI, etc). Having said that, let’s look at the advantages and challenges of the open source solution, JMeter, and contrast that with a cloud-based commercial offering.
Key JMeter Advantages:
- 100% Java application so it can be run on any platform (windows, osx, linux) that can run Java.
- Ability to test a variety of types of servers – not just front end HTTP servers. LDAP, JMS, JDBC, SOAP, FTP are some of the more popular services that JMeter can load test out of the box.
- Extensible, plug-in architecture. The open source community is very active in development around JMeter plugins and many additional capabilities exist to extend reporting, graphing, server resource monitoring and other feature sets. Users can write their own plugins if desired as well. Depending on how much time and effort is spent there is little that JMeter can’t be made to do.
- Other than the time to learn the platform there is no software cost of course since it is open source. This may be of particular value to development teams with limited budget or who have management teams who prefer to spend on in-house expertise versus commercial tools.
- It can be easy to point the testing platform at a development server and not have to engage the network or server team to provide external access for test traffic. It’s worth noting that while this is easier it is also less realistic in terms of real world results.
Key JMeter Disadvantages:
- Being that it is open source you do not have an industry vendor to rely upon for support, development or expertise. This doesn’t mean that JMeter isn’t developed well or that the community isn’t robust – quite the opposite. Depending on the scope of the project and visibility of the application it can be very helpful to have industry expertise available and obligated to assist. Putting myself in a project manager’s shoes, would I be comfortable telling upper management, “we thoroughly tested the application with an open source tool with assistance from forums and mailing lists?” if there were to be a major scale issue discovered in production?
- It’s very easy to end up with test results that aren’t valid. The results may be highly reliable – but reliably measuring bottlenecks that have nothing to do with the application infrastructure isn’t terribly useful. Since JMeter can be run right from a desktop workstation, you can quickly run into network and CPU bottlenecks from the testing platform itself – ultimately giving you unrealistic results.
- Large scale tests – not in the wheelhouse of JMeter. Right in the documentation (section 16.2 of best practices) is a warning about limiting numbers of threads. If a truly large scale test is required you can build a farm of test servers orchestrated by a central controller, but this is getting pretty complicated, requires dedicated hardware and network resources, and still isn’t a realistic real-world scenario anyway.
- The biggest disadvantage is inherent in all on-premise tools in this category in that it is not cloud based. Unless you are developing an in-house application and all users are on the LAN, it does not makes a ton of sense to rely (entirely) on test results from inside your network. I’m not suggesting they aren’t useful but if users are geographically distributed then testing in that mode should be considered.
- Your time: doing everything yourself is a trap many smart folks fall into, and often times at the expense of project deadlines, focus. Your time is valuable and in most cases it could be better spent somewhere else.
This discussion really boils down to if you like to do things yourself or if the project scope and criticality dictate using commercial tools and expertise.
For the purposes of general testing, getting familiar with how load testing works and rough order of magnitude sizing, you can certainly use open source tools on your own – with the caveats mentioned. If the application is likely to scale significantly or have users geographically distributed, then I do think using a cloud based service is a much more realistic way to test.
In addition to the decision of open source versus commercial tools is if professional consulting services should be engaged. Testing should be an integral part of the development process and many teams do not have expertise (or time) to develop a comprehensive test plan, script and configure the test, analyse the data and finally sort out remediation strategies on their own.
This is where engaging experts who are 100% focused on testing can provide real tangible value and ensure that your application scales and performs exactly as planned.
A strategy I have personally seen work quite well with a variety of complex technologies is to engage professional services and training at the onset of a project to develop internal capabilities and expertise, allowing the organization to extract maximum value from the commercial product of choice.
I always recommended to my customers to budget for training and service up front with any product purchase instead of trying to shoe-horn it in later, ensuring new capabilities promised by the commercial product are realized and management is satisfied with the product value and vendor relationship.
——
 This post was written by Peter Cannell. Peter has been a sales and engineering professional in the IT industry for over 15 years. His experience spans multiple disciplines including Networking, Security, Virtualization and Applications. He enjoys writing about technology and offering a practical perspective to new technologies and how they can be deployed. Follow Peter on his blog or connect with him on Linkedin.
This post was written by Peter Cannell. Peter has been a sales and engineering professional in the IT industry for over 15 years. His experience spans multiple disciplines including Networking, Security, Virtualization and Applications. He enjoys writing about technology and offering a practical perspective to new technologies and how they can be deployed. Follow Peter on his blog or connect with him on Linkedin.
Don’t miss Peter’s next post, subscribe to the Load Impact blog by clicking the “follow” button below.