During Super Bowl XLVII, Coca Cola, Axe, Sodastream, Calvin Klein had their hands full. Not so much serving online visitors as running around looking for quick fixes for their crashed websites. As reported by Yottaa.com, no fewer than 13 of the companies that ran ads during that Super Bowl saw their websites crash just as they needed them the most.
During Super Bowl XLVII, Coca Cola, Axe, Sodastream, Calvin Klein had their hands full. Not so much serving online visitors as running around looking for quick fixes for their crashed websites. As reported by Yottaa.com, no fewer than 13 of the companies that ran ads during that Super Bowl saw their websites crash just as they needed them the most.
If anything in this world is ever going to be predictable, a large spike in traffic when you show your ad to a Super Bowl audience must be one of those things.
Thats why one leading digital agency – ROKKAN – worked with us to guarantee the stability of their client’s campaign website just days ahead of their Super Bowl XLVIII TV commercial.
Getting this level of performance assurance not only eased their client’s concerns, it also showed how committed ROKKAN was to the quality of execution.
As with any advertising campaign, its not only about the glitz and glamour of the ad, its about the ability to motivate action on the part of the audience. And if that motivation is to visit a website, you better be damn well sure that website can take the heat and deliver an exceptional experience. Anything less translates to lost customers, degraded reputation and fewer sign ups – as was this advertiser’s campaign objective.
Background:
The auto industry was the biggest sponsor of the Super Bowl for the third straight year this year. No fewer than seven brands advertised during Fox TV’s telecast of the National Football League’s championship game on Sunday, February 2, 2014.
On average, the carmakers spend as much as $6 million per 30-second spot, for the chance to get in front of an estimated 100+ million viewers.
“When these types of investments are made, if your website doesn’t work, it becomes very ugly, very quickly for all parties involved in the campaign,” said Jim Blackwelder, chief technical officer for ROKKAN, a Publicis Groupe company that’s done award winning work for American Express, jetBlue, Chipotle, Ceasars Palace, and TAG Heuer. “Everybody just expects technology to work these days, and if it doesn’t, everyone notices.”
Test setup:
The Super Bowl Sunday challenge for ROKKAN – a 2014 Advertising Age A-List Agency for the third consecutive year – could not have been clearer: the target user load for its automaker client’s microsite promoting the features of an upcoming luxury sedan, was over 250,000 visitors per hour coming in from across the country and around the world. But initial performance tests of the website using Load Impact failed far short of that goal.
“That first test was a total eye-opener,” said Blackwelder. “Load Impact showed us we had a lot of work to do to get performance where it needed to be.”
At the advice of Load Impact, ROKKAN split performance testing to separately hit the website run by the hosting company Rackspace. The tests were done by going through and around the Rackspace content delivery network (CDN) to uncover crucial performance and configuration issues with both scenarios.
Daily meetings and testing ensued.
Challenges:
“The team at Load Impact realized that without a full court press – a really integrated effort with all of the stakeholders including ROKKAN, their service providers, as well as Load Impact – the success of the project was far from guaranteed,” said Charles Stewart, Load Impact’s general manager for U.S. operations.
Solution:
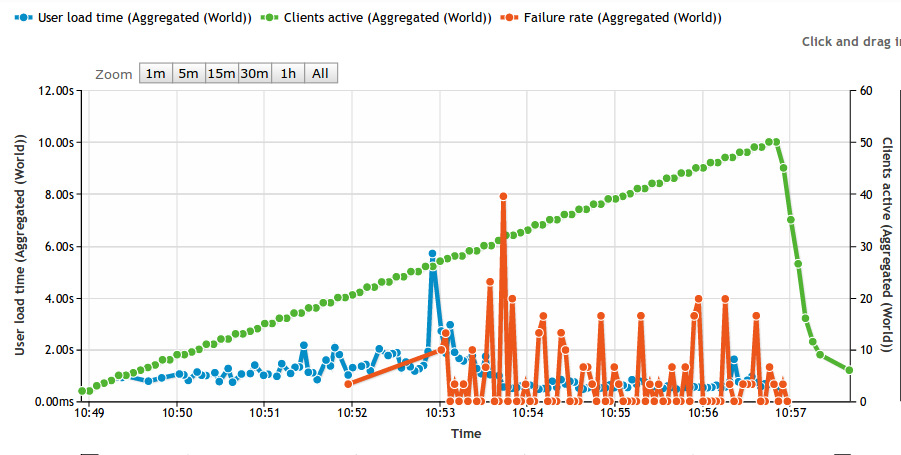
With less than one week from kickoff, ROKKAN made changes and optimizations to problems identified by Load Impact at the caching layer, application layer and hardware layer, that brought page load times to under 4 seconds with just over 10,000 simultaneous users.
It was 20 times better than when they started, but still a long way from their goal. As an added complication, eleventh hour changes requested by the automaker adversely impacted performance dramatically.
Load Impact and the ROKKAN team examined the data and identified network bandwidth as the likely cause of the performance degradation, and produced reports to support the findings.
With data in hand, Blackwelder was able to go to Rackspace’s network team, which quickly identified and resolved the remaining bottlenecks, increased throughput to the site, and gave ROKKAN’s platform the capacity it needed to scale.
Results:
The automaker’s website was ready for game day.
“Had we not done performance testing we never would have uncovered a range of issues with both our work and our partners,” said Blackwelder. “Without Load Impact our hitting the project goals and schedule would have been at risk. But it wasn’t at all. It was a huge success.”
The automaker’s site performed perfectly under the Super Bowl traffic, far exceeding expected connections per second without breaking a sweat, and delivered the customer sign-up conversions that were the automaker’s key success metric.
“For many of ROKKAN’s projects we thought of performance testing as a nice-to-have. But for this project and any of its type, it’s an absolute need-to-have. We needed large scale capacity testing, real-time viewing, and robust reporting, with a platform that could respond to change quickly, and Load Impact delivered on all counts.” – Jim Blackwelder.
———–
This is a perfect example of how NOT to waste $4 million (not including production costs). If you’ve got a big marketing campaign coming up, make sure your audience can actually fulfill the action you want them to take – performance test your campaign website/app early.